You Only Look Once: Unified, Real-Time Object Detection
从标题中可知, YOLO模型最大的特点应是”统一/实时”, 其实这是相对于R-CNN系列区域候选方法来说的. 区域候选(或者滑动窗口)方法的模型由几个不同的流程模块构成, 这就不是统一的了(一体性, unified), 由于整个模型由不同模块构成, 这又使得整个模型的耗时增加, 所以就又很难实时了(real-time).
个人觉得模型的神奇之处在于从图1的模型结构图看, 它的模块就是串行一路的, 从输入到输出的过程中, 没有一个分支. 整个模型可以分为两个部分:
- 以卷积为主的前半部分: 此部分进行一层层的卷积操作将输入图片的诸如形状, 颜色等特征进行抽象提取(数学/几何模式上, 不要从人类视觉的角度切入), 最终以前半部分的抽象特征输出为结束;
- 以全连接网络构成的后半部分: 这一部分是全连接网络, 作用是将图像像素数值的组合模式在这个网络中组合, 辅以损失函数和模型训练, 将输入图像中的像素数值模式的激活链路打通/提取出来;
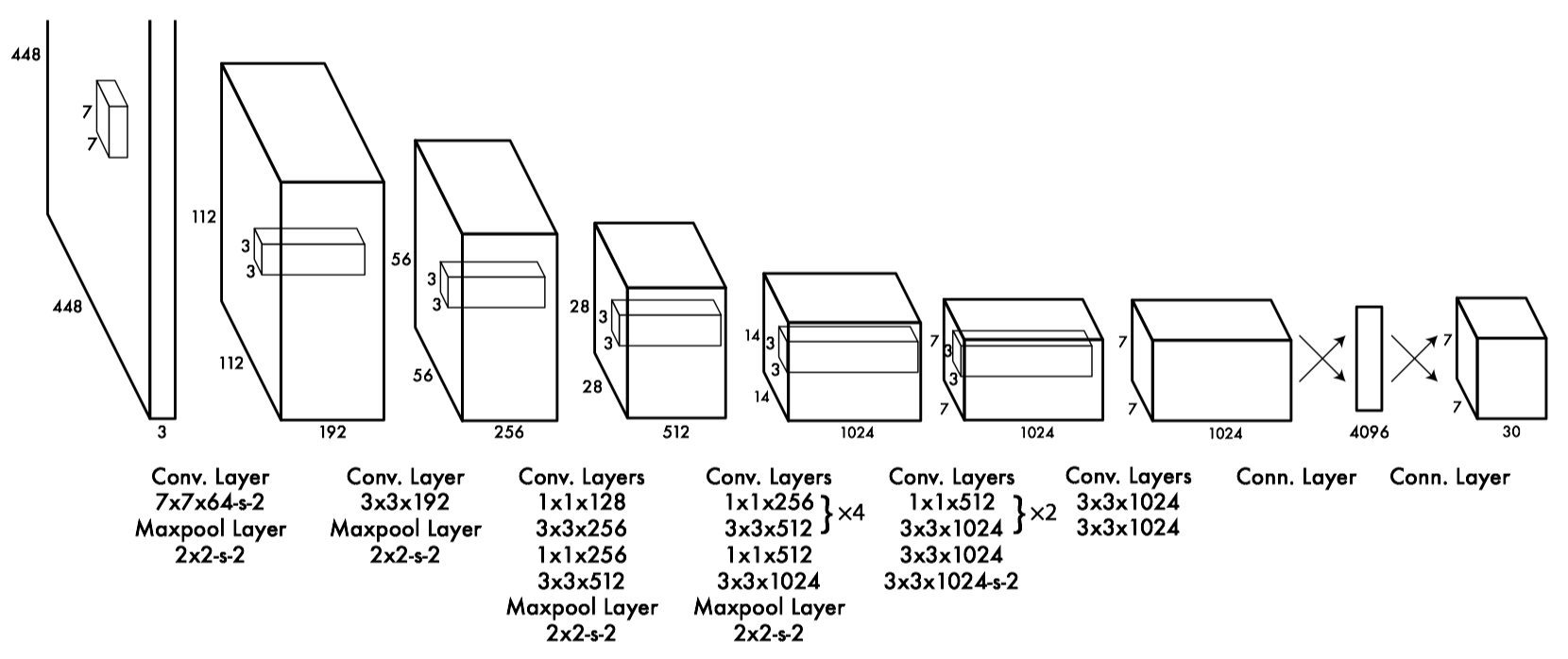
图1: YOLO模型结构图
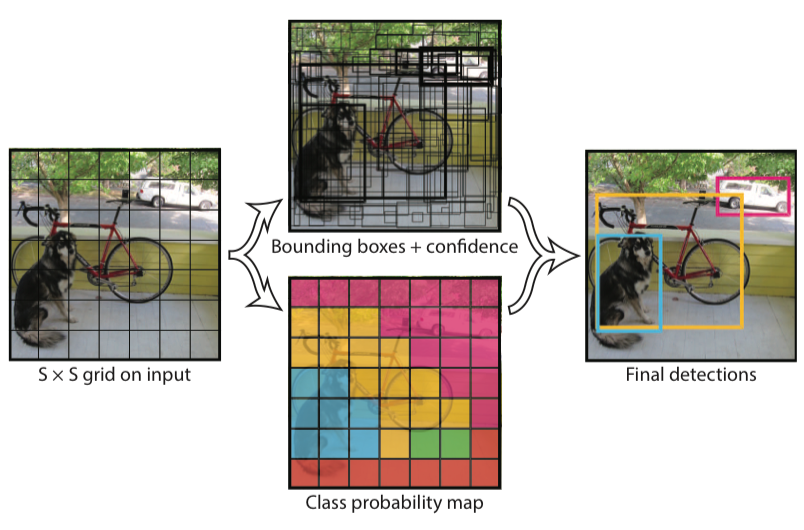
图2: YOLO的回归式检测
最终, 整个模型以7*7*30的一个Tensor(理解成3D数据结构就行, Tensor只是数学概念, 到计算机中, 还是要以数组(n维)的形式推进)介绍, 这个Tensor:
- 每个切面(slice)是7*7大小的, 对应论文中将输入图像分成7*7个方格单元(Grid Cell)的这个想法,
- 输出Tensor中30这个维度上, 分别是每个方格中预测的两个Box的10个参数(每个Box的参数: x, y, w, h和confidence(与任一有重叠的Ground Truth Box的IoU值)), 以及剩余的YOLO要预测的20个类的条件概率($Pr(Class_i|Object)$, 即当此方格中预测到有对象时才有概率输出).
这些应该与模型的训练数据关联起来(论文中貌似没详细写), 比如说训练图像的标签中应当包括: 某个方格是属于哪个Object的(这个方格中有没有Object存在[A]), 这个Object的类别是什么, 它的位置和大小(x, y, w和h)又是什么, 没有这些标签数据, 网络如何学会输出?! (个人思考是这样的)
论文给出的多组成(Multi-Part)损失函数总共由5个部分组成(总损失由下面5项相加而得), 即损失由5中子损失构成:
- $\lambda_{coord}\sum^{S^2}_{i=0}\sum^{B}_{j=0}\mathbb{ONE}^{obj}_{ij}[(x_i-\hat x_i)^2+(y_i-\hat y_i)^2]$
- $\lambda_{coord}\sum^{S^2}_{i=0}\sum^{B}_{j=0}\mathbb{ONE}^{obj}_{ij}[(\sqrt{w_i}-\sqrt{\hat w_i})^2+(\sqrt{h_i}-\sqrt{\hat{h_i}})^2]$
- $\sum^{S^2}_{i=0}\sum^{B}_{j=0}\mathbb{ONE}^{obj}_{ij}(C_i-\hat{C_i})^2$
- $\lambda_{noobj}\sum^{S^2}_{i=0}\sum^{B}_{j=0}\mathbb{ONE}^{obj}_{ij}(C_i-\hat{C_i})^2$
- $\sum^{S^2}_{i=0}\mathbb{ONE}^{obj}_{i}\sum_{c\in{classes}}(p_i(c)-\hat{p_i}(c))^2$
其中, $\mathbb{ONE}^{obj}_{i}$代表的是: 目标对象(object)是否被检测出现在方格$i$中, 而$\mathbb{ONE}^{obj}_{ij}$代表的是: 方格$i$中对象是否存在的预测由该方格所属的第$j$个(其实就两个)边界框预测器(bounding box predictor)预测得来.
那么, 上面这5个损失, 怎么用直觉性(intuition)的思路去解释呢?!
首先, 上面提到的条件类别概率(conditional class probability, 个人感觉就是示性函数, 即: $\mathbb{ONE}^{obj}_{ij}$), 在损失函数中则意味着含该条件概率的子损失函数只将该方格中检测到对象的类别的损失值计算到该损失函数中, 也即: 未检测到的对象类别的损失将不计算(很直观地: 对象都不存在, 你怎么计算/计算有什么意义, 只不过这个$\mathbb{ONE}^{obj}_{ij}$虽然简短, 但太抽象, 就像$E=mc^2$, 太抽象了, 难有生活直观经验). 在上面的5个子损失函数中, 每一个都含有条件类别概率, 即: $\mathbb{ONE}^{obj}_{ij}$项.
其次, 两个$\lambda_{coord}$和$\lambda_{noobj}$系数用于调节对应损失类别在总损失(函数)值中的比例, 在论文中, 两项值的设置为: $\lambda_{coord}=5$, $\lambda_{noobj}=0.5$. (MARK: 关于系数, 此处可扩充内容, 进行Reasoning)
关于上面5项子损失函数的释义性说明, 我叙述如下:
- 对于$S^2$个方格(7*7=49个)的98个预测BBox(每个方格预测两个Bounding Box), 我们计算它们预测边界框的中心$(x,y)$与真实值的损失(即, 欧式距离, 或L2距离, 或各维度的差的平方的和), 其中, 我们只为此项中存在的类别计算损失(示性函数, $\mathbb{ONE}^{obj}_{ij}$): 此子损失函数为98个BBox的损失总和;
- 此项子损失函数与上面一项类似, 它计算的是每个BBox的高和宽的损失;
- 此项计算的是每个BBox的条件类别概率损失(是: $P_r(Class_i|Object)$): 如果一个对象(object)出现在该方格单元(grid cell)中(论文原文是grid cell, 我觉得应该是98个BBox中的每一个), 则计算该对象的分类预测概率, 并与真实值比较, 进而得出该项分类概率损失(交叉熵, 吧);
- 略..;
- 此项计算的是, 49个方格中的分类(概率)的L2损失(差=>平方=>和), 注: 这里的损失值计算不是常见的交叉熵损失和, 另外, 我们只对检测到对象方格进行损失计算, 因为: $\mathbb{ONE}^{obj}_{i}$, 我们有20个需预测的类别, 故损失在20个类别间展开计算.
关于训练中的参数设置, 论文中给出了如下结果:
- 训练进行了135个epoch(训练/验证集, from PASCAL VOC 2007和2012), 在2012上测试时, 使用了2007的测试数据用于训练(注意是测试数据用于训练), 训练中: batch_size=64, momentum=0.9, decay=0.0005;
- 学习率(“步长”)是动态变化的: 初始几个epoch, 缓慢地将学习率从$10^{-3}$上升至$10^{-2}$, 然后使用$10^{-2}$这个值的学习率一直学习/训练到75个epoch, 接着$10^{-3}$进行30个epoch, 再接着$10^{-4}$进行30个epoch, 至此, 总共135个epoch学习完毕; (注: 论文提到如果初始阶段就上较高的学习率, 则模型不会收敛(diverge), 因为不稳定的梯度使然(unstable gradient, 应指梯度爆炸))
- 为了避免过拟合, 论文进行了: 1.丢弃(dropout), 2.数据增强(extensive data augmentation). 论文使用的丢弃层(dropout layer)是在第一个全连接层之后(说为了防止在layers之间的co-adaptation, 具体啥意思?), 丢弃率为0.5, 而数据增强则有三个措施: 1.随机缩放和平移(random scaling and translation), 最小至20%的原图大小, 2.在图像的HSV颜色空间中随机增大曝光值和饱和度值到1.5倍.
论文的目录/结构:
摘要(Abstract)
介绍(Introduction)
整体检测(Unified Detection)
2.1 网络(结构)设计(Network Design)
2.2 训练(Training)
2.3 预测推理(inference)
2.4 YOLO的不足(Limitations of YOLO)
与其它检测系统的比较(Comparison to Other Detection Systems)
实验(Experiments)
4.1 与其它实时系统比较(Comparison to Other Real-Time Systems)
4.2 VOC 2007错误分析(Error Analysis)
4.3 将Fast R-CNN与YOLO结合(Combining Fast R-CNN and YOLO)
4.4 VOC 2012上的结果(Results)
4.5 泛化性: 在艺术作品中的人物检测(Generalizability: Person Detection in Artwork)
实际环境中的实时检测(Real-Time Detection In The Wild)
结论(Conclusion)
https://blog.csdn.net/lilai619/article/details/79695109
https://blog.csdn.net/qq_34806812/article/details/81673798
https://blog.csdn.net/duanyajun987/article/details/88717332
https://pan.baidu.com/s/1wEtpdQBuMtXn_9CGhEvHTQ
https://pjreddie.com/darknet/yolo/
https://pjreddie.com/publications/
https://blog.csdn.net/shuiyixin/article/details/82533849
https://www.jianshu.com/p/a2a22b0c4742
MMMMMM
Reference
- 简书翻译: https://www.jianshu.com/p/a2a22b0c4742, 实际没怎么看(这里只Mark): 要想看懂论文逻辑, 无他, 唯手熟尔(没有捷径的);