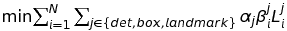MTCCN: Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks (2016)
0.摘要解读 Abstract - Face detection and alignment in unconstrained environment are challenging due to various poses, illuminations and occlusions. Recent studies show that deep learning approaches can achieve impressive performance on these two tasks. 文意转义: 人脸检测与对齐(找到几个关键点: 嘴, 鼻子, 眼睛)在开放环境(unconstrained)是一件挑战性的事情. (如果你在阅读时发现公式没有被渲染, 请用Chrome浏览器并安装使用插件:”Math Anywhere”[REF], 这是一个暂时不完美解决方法)
In this paper, we propose a deep cascaded multi-task framework which exploits the inherent correlation between them to boost up their performance. In particular, our framework adopts a cascaded structure with three stages of carefully designed deep convolutional networks that predict face and landmark location in a coarse-to-fine manner.
在此篇论文中, 将会提出深度层叠多任务的一个框架, 此框架挖掘出这些任务间的内在关联并提升(boost up)了它们的表现. 具体的, 论文提出的框架采用了一个三阶段的层叠(cascade)结构, 而其中的每个阶段都是经过精心设计的一个深度卷积网络, 即后面要讲到的Proposal, Refine, Output 网络.
In addition, in the learning process, we propose a new online hard sample mining strategy that can improve the performance automatically without manual sample selection. Our method achieves superior accuracy over the state-of-the-art techniques on the challenging FDDB and WIDER FACE benchmark for face detection, and AFLW benchmark for face alignment, while keeps real time performance.
此外, 在学习过程中, 论文也提出了一项新的在线(即及时)难例挖掘策略(它能自动提升性能, 且不需要手工筛选采样). 论文的模型方法在人脸检测中超越了FDDB和WIDER FACE这两个基准模型(benchmark), 在人脸对齐中超越了AFLW基准模型, 且都保持了实时性.
Index Terms—Face detection, face alignment, cascaded convolutional neural network (检索关键字: 人脸检测, 人脸对齐, 层叠CNN)
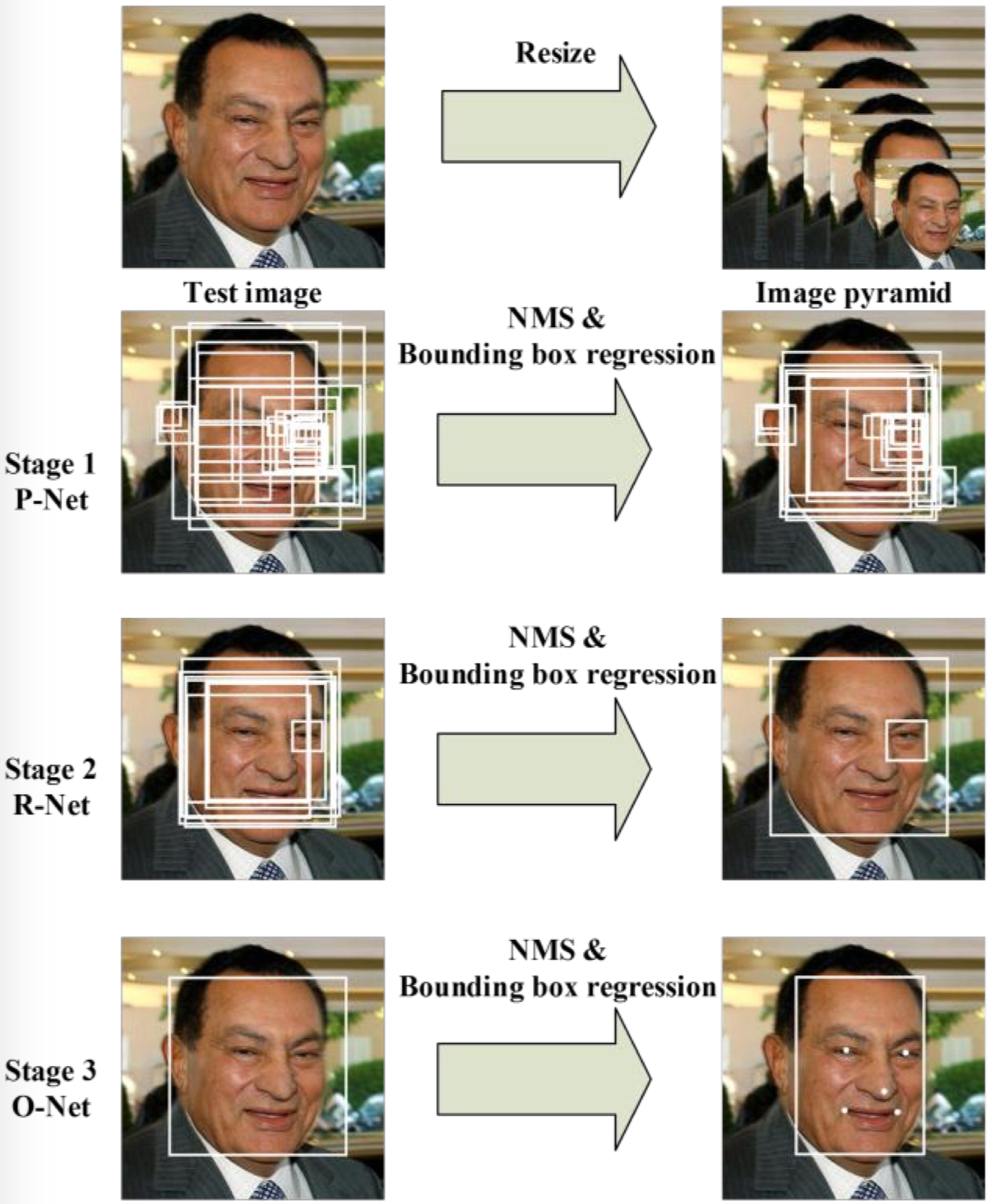
图1: 层叠结构的三个任务步骤
1.论文第II部分(Approach, 理论方法)要点笔记
此部分是论文关键性算法的一个阐释, 但如果要在里面找代码实现性的Solution, 会抓狂失望的, 因为, 这部分只有分散的某些局部算法, 却构不成整体宏观视角.
A. Overall Framework
MTCCN模型结构的流程(pipeline)如图1所示, 以下则是对应的描述:
- 首先, 将一个输入图像Resize成不同Scale的, 构建一个系列不同大小的图集(放置在一起有如金字塔形): test image => image pyramid;
- Proposal Network(P-Net): 获取候选Window(candidate windows)及它们相应的边界框回归向量(bounding box regression vector, 用引用[29]中的方法), 之后, 使用预估后的上述回归向量去调整候选框(的具体坐标位置), 并使用非极值抑制(Non-Maximum Suppression, NMS)剔除那些高度重叠却不是极值的框;
- Refine Network(R-Net): (上一步中的)候选window(图片中的某块区域)输入到此R-Net中, 通过以下校准(calibration)操作排除输入中假(false)的候选window: 边界框回归, 及NMS;
- Output Network(O-Net): 同上一步类似(的模型网络结构), 但这一步更具体: 输出5个脸部标志位置(landmark position), 即两眼, 鼻子, 嘴巴两端.
以上步骤1-3中的网络模型结构如图2所示.
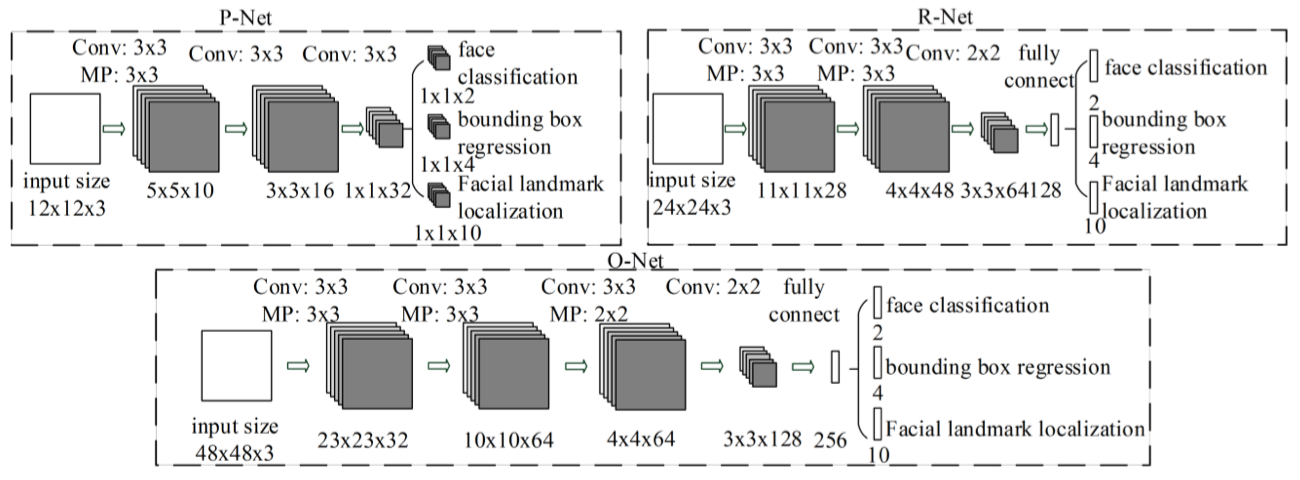
图2: 3个模型的具体结构
B. CNN Architecture
此小节给出在引用[19]中人脸检测性能受限的可能两个因素:
- 一些过滤器缺乏权重的多样性(How/Why?!), 此种情况可能限制它们生成(对于(人脸)特征的)区分/识别性描述(discriminative description)(的能力);
- 相对于其它多类别对象检测和分类任务, 脸部检测是种有挑战的二分类任务: 它需要的是可能少一点的过滤器但更具识别性的能力.
对此, 论文中的做法是: 减少过滤器数量, 过滤器(尺寸)由5*5改成3*3(减少计算量?!), 增加模型网络深度. 随后, 论文给出表1证明以上改进比引用[19]中的模型有更好的性能: 更佳的表现, 更少的耗时(为保证对比的公平性, 两者使用相同的数据).
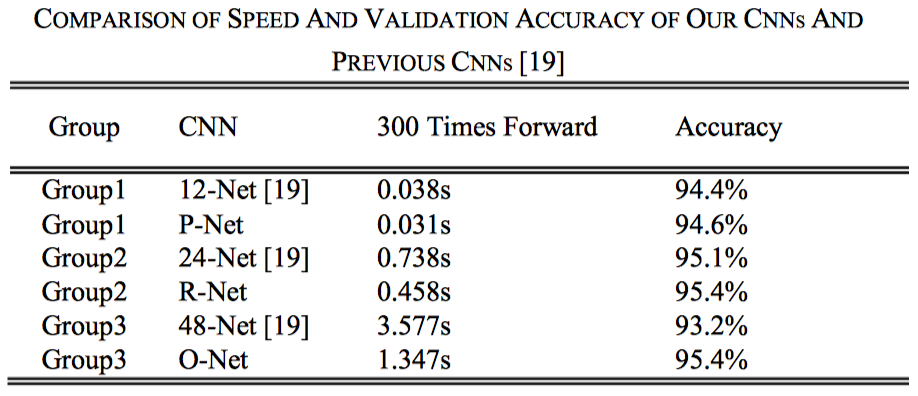
表1: MTCCN与其它模型对比
C. Training
关于训练的设置: 包括几个网络的损失函数, 数据难例挖掘等.
2.论文第III部分(Experiments, 实验细节)要点笔记
论文使用了三个任务训练每个CNN检测器(三个P/R/O子网络): 1.脸/非脸分类, 2.边界框回归, 3.脸部标志定位, 即, 在每个子网络中各自训练这三项任务.
1) Face classification: 这项任务是(二元)分类任务, 对于每个输入(样本)$x_i$, 论文使用的损失计量方法是:
$L^{det}_i=-(y^{det}_ilog(p_i)+(1-y^{det}_i)(1-log(p_i)))$
其中, $p_i$是网络预测这个输入是人脸的概率, 标记$y^{det}_i$是含两个值的实际值集合$\{0,1\}$.
2) Bounding box regression: 对于边界框的回归, 论文中使用欧式距离(即几项坐标差的平方)作为损失的计量方式: 让模型最后的输出坐标去拟合(通过损失函数的定义及后向传播)距离最近的真实值的坐标, 该损失函数为:
$L^{box}_i=||\hat y^{box}_i-y^{box}_i||^2_2$
其中, $\hat y^{box}_i$是网络给出的预测值(即输出), 而$y^{box}_i$则是该数据的真实(坐标)值了, 四个坐标值分别为: 边框左上角的x和y, 高度height和宽度width, 所以: $y^{box}_i\in\mathbb{R^4}$(此向量属于4维实数空间).
注: 特征向量能用于回归(或是分类, 或是landmark标记学习), 是因为这个输入的特征向量(或说feature map)中含有我们的关注的以及不关注的对象的特征, 如关注的是人脸, 不关注的可以是背景或其它不需要学习的对象, 当我们告诉网络这些特征的最终目标(或说定义损失的计量方法)时, 就决定了这些我们关注的特征将产生怎样的结果: 分类, 人脸坐标(location), 关键点坐标(landmark loc.).
此外, 以下这一点理解也不能缺少: 以上是一个数据的特征与结果的关联, 如果说就用一个样本数据就能学会上述任务我觉得很玄学, 这就是我们为什么需要大量数据以及随机梯度的原因了.
在不同的人脸图像数据中人脸的坐标位置一般都是不一样的, 那么, 当我给你一个新的人脸, 你怎么就能预测它的位置了?! 因为虽然是不同位置的人脸, 但只要是人脸, 在网络靠后(或是最后)的feature map中, 肯定有它对应的激活神经元, 而因为它们在原图中的位置不同, 所以在一层层的卷积(及其它网络计算)到最后的feature map层之后, 人脸对应的激活神经元会不同, 我们预测位置, 不就要根据不同位置的神经元来做位置回归吗?! 在使用大量数据时, 就是就是告诉网络: 这是个人脸, 它的位置是这个, 下次来别的人脸图像, 你的参数要给力要能预测出位置来.
(上述讲解没有配图(如何配?), 我先将自己对于这个”人脸/位置回归”网络抽象概念的理解, 梳理一遍, 希望也能有助于本文阅读者)
3) Facial landmark localization: 此部分的学习任务, 原理上与上一部分”边框回归”的一模一样(同样的”特征图+坐标”回归形式), 只不过现在要回归的对象是我们规定好的五个位置: 两眼, 鼻尖, 嘴唇两端, 这些点的坐标在训练数据中会给出(此种训练数据与普通的分类数据也是不一样的: 标签/标定值不同), 此处, 损失函数为:
$L^{landmark}_i=||\hat y^{landmark}_i-y^{landmark}_i||^2_2$
我们要预测的眼部标志位置有5个, 共10个坐标维度, 故: $y^{landmark}_i\in\mathbb{R^{10}}$.
4) Multi-source training:
对于P/R/O网络中最后的三种训练任务, 它们所需要的数据集会有所不同(如face, non-face和partially aligned face的数据集), 为此, 论文对每个训练任务采用了不同权重的损失计算比例(系数$\alpha$):
- P-Net和R-Net: $\alpha_{det}=1$, $\alpha_{box}=0.5$, $\alpha_{landmark}=0.5$;
- O-Net: $\alpha_{det}=1$, $\alpha_{box}=0.5$, $\alpha_{landmark}=1$.
在O-Net中, 其$\alpha$系数增大了(为1), 是想对脸部标志点有更多的权重更新(比重大, 损失值增加了), 以下, 给出论文中对于每个子网络总损失的计算公式(两次求和):
其中, $\beta^j_i\in\{0,1\}$是此样本类别的指示值(indicator)(指示是否是人脸), 以上设置中, 使用SGD(随机梯度下降)训练CNN(“it is natural to employ sgd…”).
5) Online Hard sample mining:
不同于传统的hard sample mining方法(指在分类器训练完之后再进行mining), 论文中使用online mining策略, 以适应(adaptive)训练的过程, 具体方式为: 在每个(mini)batch的前向过程(forward propagation)中, 将损失值为top 70%的那些样本标定为困难(hard)样本, 在后项传播(backward propagation)中只更新这些样本权重的梯度(gradient).
(这样操作, 意味着训练过程忽略那些不太能强化模型(detector)的容易样本(easy samples), 实验也表明它的效果比没有人工样本选取的参与(without manual sample selection)要好)
3.实验部分 / EXPERIMENTS
这一部分论文主要做了以下事情: 1.论文评估了上一部分提出的难例挖掘策略的效果(effectiveness), 2.将论文的人脸检测和对齐模型与其它模型(FDDB, WIDER FACE, AFLW)对比, 3.评估模型人脸检测的计算效率(computational efficiency).
注: 以上数据集的缩写分别为: Face Detection Data Set and Benchmark(FDDB), WIDER FACE(无缩写), Annotated Facial Landmarks in the Wild(AFLW).
A. Training Data
四种模型训练时的数据标记: 1.负例(Negatives, 与GT标记的脸的IoU小于0.3), 2.正例(Positives, IoU>0.65), 3.部分脸(Part faces, IoU介于0.4与0.65之间), 4.标志脸(Landmark faces, 此数据含有全部5个脸部标志). (其余略)
B. The effectiveness of online hard sample mining
论文训练了两个O-Nets用来对比有与没有online hard sample mining的效果, 且为了更直接地比较效果, 只对O-Nets的人脸分类任务进行了训练, 结果如下图3左:
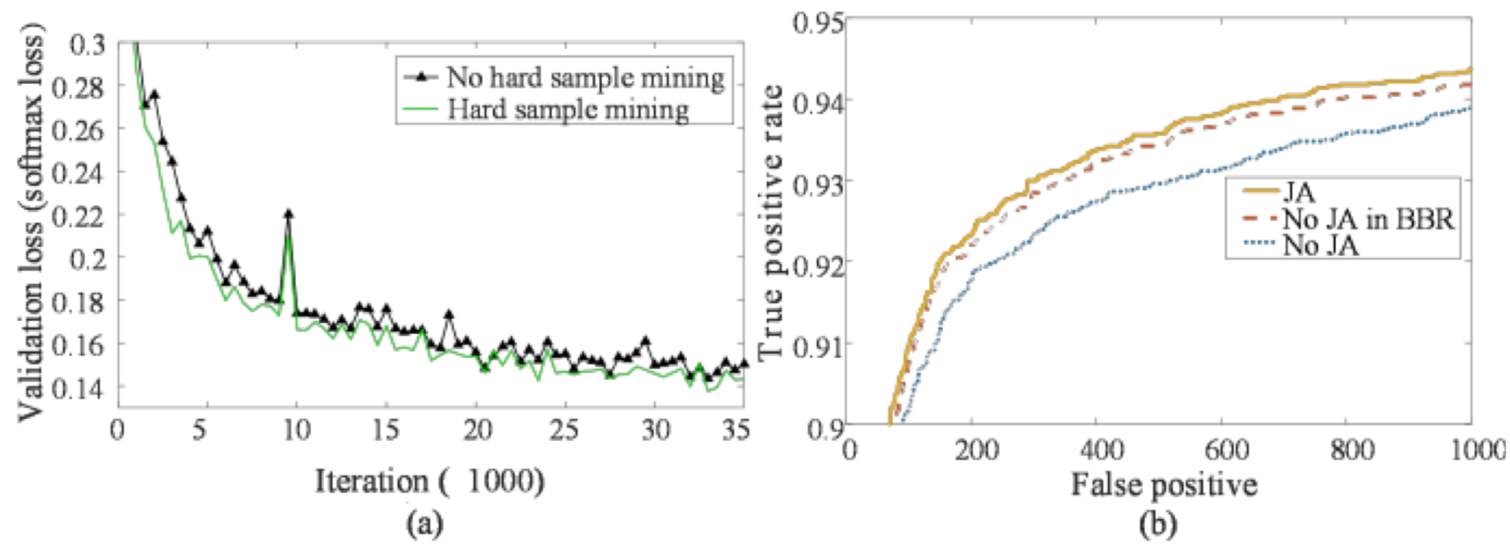
图3: O-Net的Online Hard Sample Mining效果比较(左图). 图注: (a) Validation loss of O-Net with and without hard sample mining. (b) “JA” denotes joint face alignment learning while “No JA” denotes do not joint it. “No JA in BBR” denotes do not joint it while training the CNN for bounding box regression.
C. The effectiveness of joint detection and alignment
此处论文讲述的是将人脸检测与对齐一起(joint)训练时带来的好处, 论文中也引入了边界框回归的效果比较, 结论是联合脸部标志一起训练(joint landmarks localization task learning)对人脸分类和边界框回归都具有好处(图3右).
D/E. Evaluation on face detection/alignment
此部分(D)论文展示了一些使用了FDDB和WIDER FACE数据集并有不错(state of the art)人脸识别效果的方法, 并且罗列在图4的(a-d)子图中, 可以看出, 论文的方法超过了基准模型一大截(a large margin), 而E部分, 论文将模型的对齐表现与RCPR等7个方法进行了比较, 其效果要好于这几个模型(图4底).
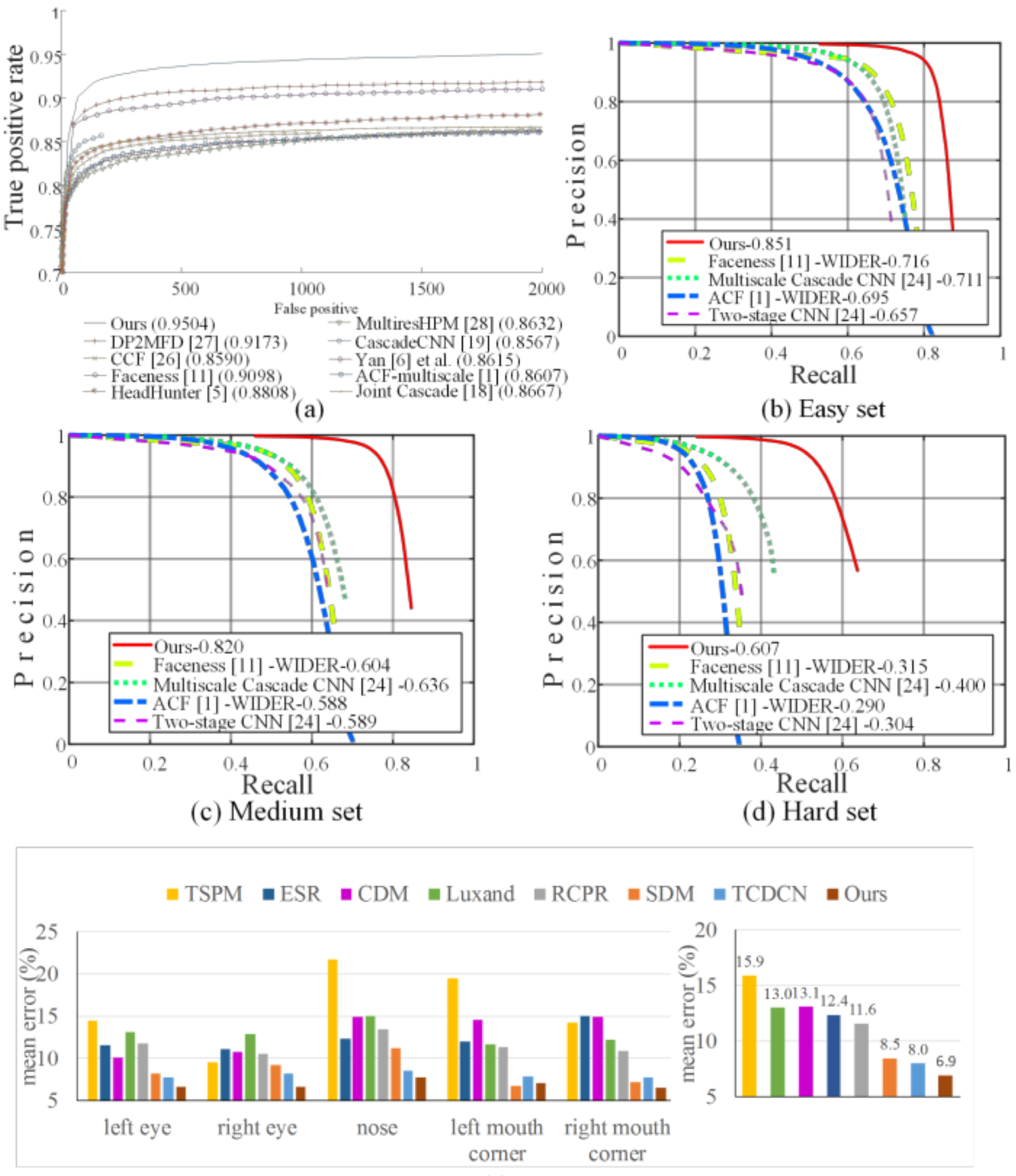
图4: MTCCN与基准模型的人脸检测与对齐比较
F. Runtime efficiency
论文说了其方法在人脸检测和对齐(联合任务)中很快, 因为使用了层叠结构, 具体的, 在2.6GHz的CPU中速度是16fps, 在GPU(Nvidia Titan Black)中是99fps, (而且)实现在未经优化的MATLAB代码上.
4.结论
论文为人脸检测和对齐(联合)任务提出了多任务及层叠CNN的模型结构, 该结构方法在超越不错的基准模型时还保持了实时性. 后续中, 论文作者会探索发掘人脸检测和其它人脸任务之间的内在关联(inherent correlation), 以进一步提高性能(没说什么的性能).
文末素材格式区(请忽略)
$\sum_{i=0}^N\int_{a}^{b}g(t,i)\text{d}t$