AlexNet的”官方”论文为ImageNet Classification with Deep Convolutional Neural Networks [ref], 发表于2012(7年前, :)), 论文的三位作者分别是Alex(第一作者), Ilya和Geoffrey Hinton(前两位的导师), 其中的Dropout概念, 应当是很有影响的概念了.
此篇论文共7个章节, 下面我将论文的读后理解札记下来, 输出出来加深印象.
(Abstract)
- Introduction
- The Dataset
- The Architecture
- Reducing Overfitting
- Details of learning
- Results
- Discussion
(Reference)
(Abstract)
概括了作者要提出的模型的一些简要情况: ILSVRC-2010的top-1和top-5的错误率为37.5%和17.0%的一个模型(比之前的都要好), 以及这个模型有6,000万个参数(注: VGG(A)/133万, VGG(E)/144万)和6.5万个神经元. 该模型使用的一些技巧, 有:
卷积层5个(后接最大池化层)和3个全连接层(其中两个应用了Dropout),
非饱和神经元(即ReLU, 为了加速训练),
GPU的使用.
使用该模型的一个变化版本, 在ILSVRC-2012得到了15.3%的错误率(top-5).
1.Introduction
该部分首先简述了小数据集(几万张的级别)的作用: 在简单的识别任务中(如MNIST数字识别), 这样的数据集可以适用和胜任. 然后, 说明了在真实环境中对象是会变化的(variability, 注: 如角度, 成像大小等), 引出我们需要更大的数据集的需求, 并提到了其中两个: LabelMe和ImageNet.
接着该部分的第二段, 提到了模型的学习能力(learning capacity, 学习什么?! 识别对象): 即便有了像ImageNet这样的大数据集, 由于对象识别任务的巨大复杂性(immense complexity, 没法靠人工去一一指定), 也不可能将对象识别这个任务明确指定好(具体如何识别对象). 继续, 文中提到CNN, 提及CNN的学习能力(匹配识别对象的复杂度)可由CNN模型的深度(depth)和广度(breadth)控制.
接下去的三段, 主要内容为: 1.CNN与GPU与数据, 2.论文的几点重要贡献罗列, 3.论文中网络的尺寸(受限于GPU内存与训练时间).
2.The Dataset
这一部分, 先是介绍了ImageNet(1,500万高分辨率图像, 22,000个类别), 而ILSVRC使用的是ImageNet的一个子集. 然后, 在下一段, 论文说明了测试集标签的问题: ILSVRC-2010是ILSVRC竞赛中唯一有测试集标签的版本(大多数实验都在此版本上进行), 论文中使用了top-1和top-5错误率作为报告的错误率.
最后一段, 讲述了论文处理图像分辨率的方式: 短边缩放至256的值, 并裁剪长边为256. 另外, 论文方法也对整个训练集的图片进行了”减去平均活跃值”(mean activity)的处理.
3.The Architecture
该部分主要讲述模型的架构(8个主要网络层 = 5个Conv + 3个FC), 以及网络中使用到的一些特性(ReLU, 多GPU训练等).
首先, 在3.1节ReLU Nonlinearity中, 论文对比了饱和非线性性(saturating nonlinearity, 如tanh函数)和非饱和非线性性(non-saturating nonlinearity, 此处的ReLU函数), 指出ReLU加快了网络的训练(图1).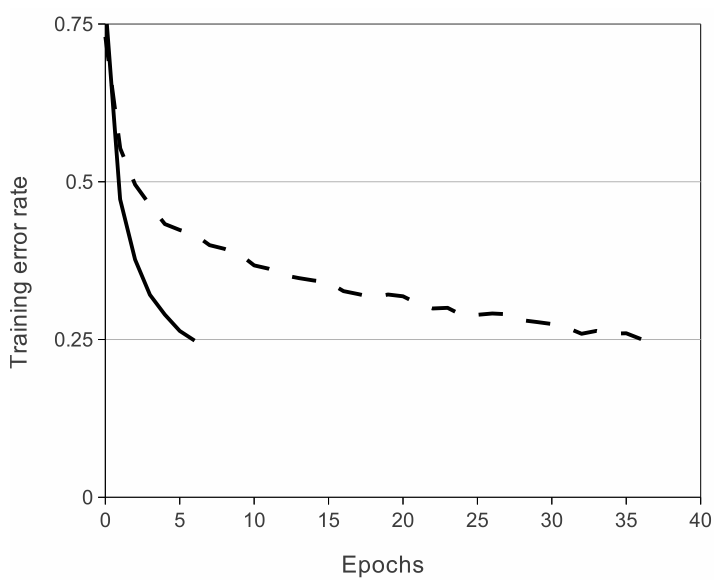 {:height=”250”}
{:height=”250”}
(图自: 论文 Figure 1)
其次, 在3.2节”Training on Multiple GPUs”中, 提到受限于GPU内存的大小(论文使用的GPU内存为3GB), 故将网络分布在两个GPU上进行训练, 此并行方案是: 基本上, 每个GPU放置一半的核; 另外, 在第3层时进行GPU间的通信: 第3层的核(分别在两个GPU中)会将第2层的所有feature map(两个GPU中所有的)同时作为输入进行卷积运算.
接下去, 论文的3.3节”Local Response Normalization”和3.4节”Overlapping Pooling”分别讲述了这两种技术(局部响应归一化, 重叠池化), 但现在这两种技巧并不被经常使用(?!).
最后, 3.5节”Overall Architecture”描述了AlexNet模型的总体架构, 为5个卷积层与3个全连接层的”一个序列”, 具体有如下图的结构: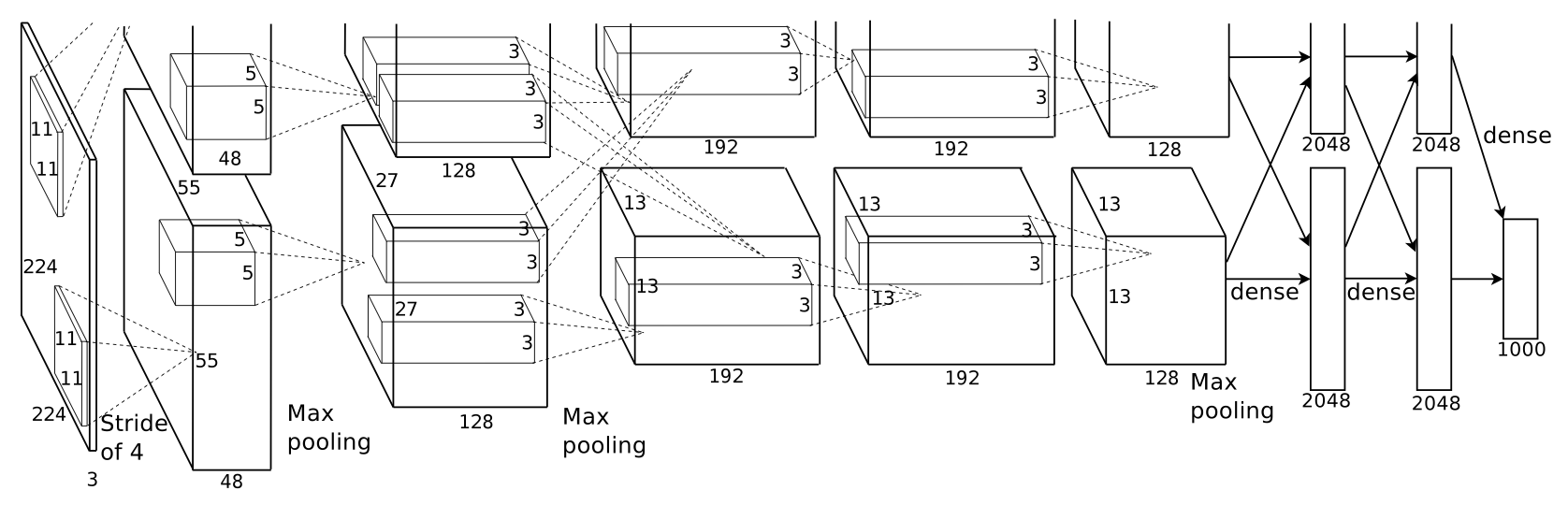
(图自: 论文 Figure 2)
4.Reducing Overfitting
在这一部分, 论文提及到了减小过拟合的两个主要方式(数据增强, Dropout), 这么做的原因是因为网络架构的参数有6,000万个(很多, 多于数据集的scale), 会产生过拟合.
在4.1节”Data Augmentation”中, 论文提及了两种数据增强的方式: 1.图像变换和水平翻转(裁剪出224x224的图像块), 2.改变训练集图像RGB通道的强度(对像素值集合执行PCA并对图像加上多倍找到的主成分).
在4.2节”Dropout”中, 论文介绍了这一概念, 以及它的应用位置: 在三个全连接层的前两层的输出中应用.
5.Details of learning
此部分具体讲述了论文模型的训练细节: 如参数设置, 参数初始化等. 在模型训练中, 论文团队使用了SGD(随机梯度下降, batch_size=128), 动量(=0.9), 权重衰减(=0.0005)等设置.
6.Results
论文的神经网络在ILSVRC-2010数据集上的结果有top-1 37.5%和top-5 17.5%的表现, 这在当时(2012年及以前)来说, 是已公布结果中最好的(ILSVRC-2010竞赛的最佳结果是: top-1 47.1%, top-5 28.2%). 另外, 论文也涵盖了所涉模型在ILSVRC-2012竞赛(测试集标签不公开)中的结果.
7.Discussion
讨论部分, 论文总述大型深度卷积神经网络(A large, deep convolutional neural network)可以取得的破纪录结果, 并佐证深度的重要性: 在论文的模型中, 移除任何中间层都会导致大约2%的top-1性能损失.
最后, 论文进行了一些模型之外的探讨.